项目初衷 编写此项目目的是为了记录自身在使用Python时,由脚本过度向项目的转变,作为一个非coder出身的小菜鸡,这其中更像是一个日常渗透接到开发任务后的心态转变,所以本文记录的内容偏向于基础。
文内包含
Python后台部署 Python项目部署过程中还是踩过很多坑的,此处对自己部署Python项目时踩过的坑,以及现阶段我所使用的技术栈做一个规划
定时任务篇 schedule Python脚本编写过程中,定时任务是一个逃不过的小坎,最初使用定时任务时,最常用的模块就是“schedule”,那流畅的every.day,流畅的while循环……
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import scheduleimport timedef job (name ): print ("working : " , name) name = "shui" schedule.every(10 ).minutes.do(job, name) schedule.every().hour.do(job, name) schedule.every().day.at("10:30" ).do(job, name) schedule.every(5 ).to(10 ).days.do(job, name) schedule.every().monday.do(job, name) schedule.every().wednesday.at("13:15" ).do(job, name) while True : schedule.run_pending() time.sleep(1 )
上面是schedule库使用的样例,其含义分别如下所示
1 2 3 4 5 6 - 每隔十分钟执行一次任务 - 每隔一小时执行一次任务 - 每天的10:30执行一次任务 - 每隔5到10天执行一次任务 - 每周一的这个时候执行一次任务 - 每周三13:15执行一次任务
最后通过while死循环中的schedule.run_pending()去执行任务,但是问题来了,他是怎么知道这个时间点就是job中规定的时间点呢
出入编程门槛的无知少年当是满心欢喜的执行着脚本,哪儿还管他什么是while循环,哪儿还管他什么是执行逻辑,但是现在回头总结时,终归是要做一下试验,避免其他人在去踩坑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import scheduleimport timedef MinutesJob (time ): print ("分钟定时任务:" , time) def DayJob (time ): print ("日定时任务:" , time) NowTime = time.strftime("%H:%M:%S" ) schedule.every(10 ).minutes.do(MinutesJob, NowTime) schedule.every().day.at("10:00" ).do(DayJob, NowTime) while True : schedule.run_pending()
上述测试demo运行后,确实如我们预期一样,到了该执行的时间去执行
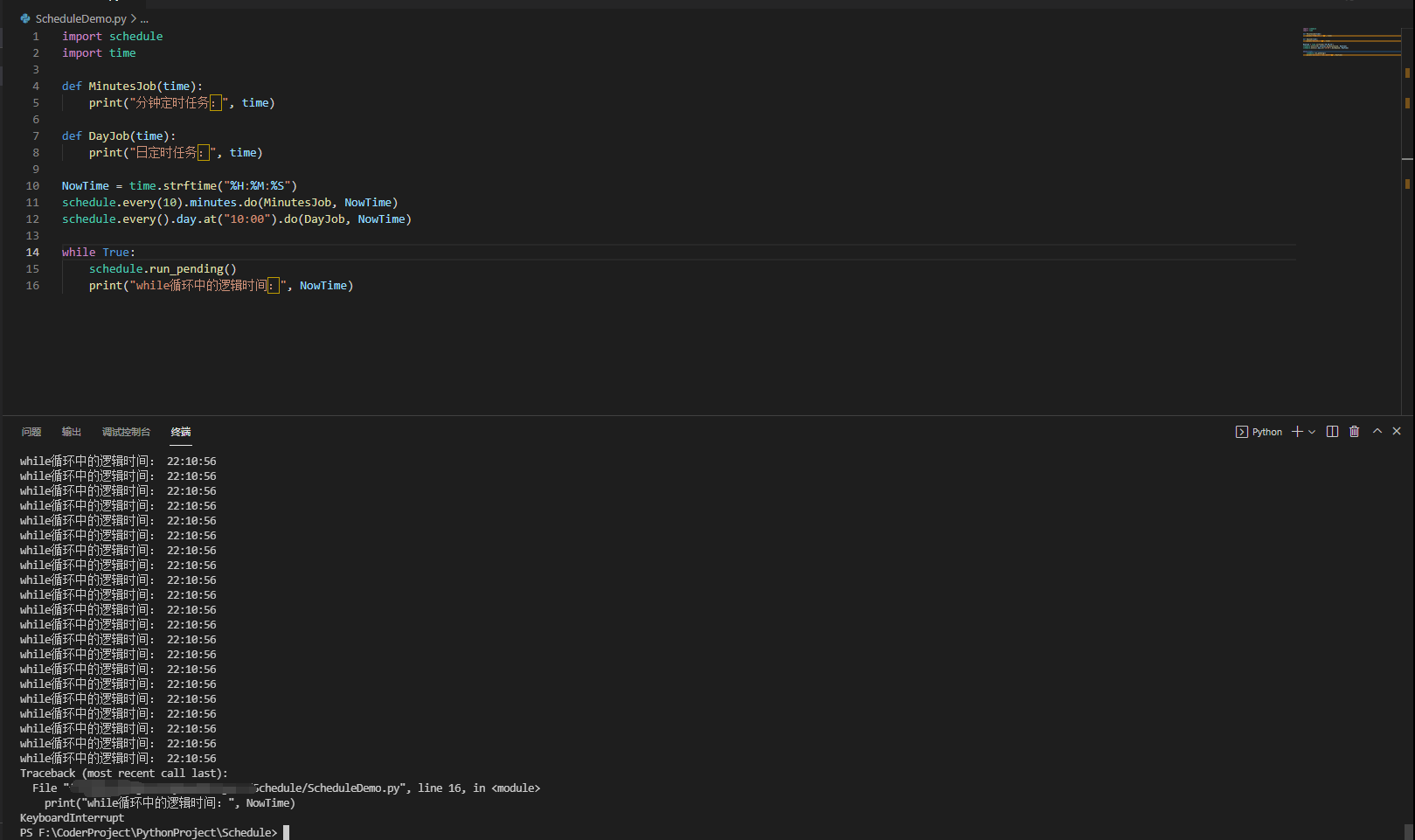
但是在while循环中增加一个print就可以看到如下的情况
很吓人的无限死循环,且每时每刻都在做时间的读取;是想,如果将这段程序运行在服务器上,那么造成多少资源浪费;咳咳,恰巧,本人在刚开始编写Python定时任务的项目时,有很长一段时间将schedule当做宝一样。
crontab 那么问题来了,既然这个库这么坑,有没有更好的平替呢?
crontab,它踏着脚本走来了
Linux crontab是用来定期执行程序的命令。
当安装完成操作系统之后,默认便会启动此任务调度命令。
crond 命令每分钟会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。
其执行命令格式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 // 进入crontab定时任务编辑模式,如果是初次使用,会有弹窗选择编译器,建议使用vim crontab -e // 查看现有的crontab任务 crontab -l // crontab编辑定时任务的时间格式如下 f1 f2 f3 f4 f5 program - 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程序。 - 当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其馀类推 - 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推 - 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推 - 当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推 * * * * * - - - - - | | | | | | | | | +----- 星期中星期几 (0 - 6) (星期天 为0) | | | +------- 月份 (1 - 12) | | +--------- 一个月中的第几天 (1 - 31) | +----------- 小时 (0 - 23) +------------- 分钟 (0 - 59)
格式化的描述可能有点模糊,最简单的举例:
1 2 3 //每天上午十点定时执行sh脚本 00 10 * * * bash /tmp/CrontabDemo.sh
因此使用crontab就可以轻松的实现Python3的定时任务执行,虽然可以直接使用Python挂crontab执行,但是本人更喜欢编写start启动脚本
1 2 3 4 5 6 7 8 9 10 // Start.sh cd /tmp/CrontabDemo/source venv/bin/actionpython3 CrontabDemo.py // crontab定时任务 00 10 * * * bash /tmp/CrontabDemo/Start.sh
通过上述的操作,即可将Python的脚本挂载定时任务,无需Python自身编写死循环去判断时间,进而在去执行。
不过需要注意的一点是,crontab在创建定时任务后,不会立刻生效,而是有2 - 3分钟的延时 ,虽然对于编程人员来说,这个时间区间很不严谨,但是本人确实没有掐着表计算这个具体时间,望见谅。
后台执行篇 screen 之所以引入后台执行的概念,本质在于任何执行的脚本,关闭当前编译窗口后,线程会直接奔溃,正在运行中的脚本也会随之中断,所以,必须引入后台执行逻辑
Linux中最先接触到的是screen的后台执行,个人理解其逻辑在于开启一个新的窗口,执行脚本后,退出窗口,screen会自行守护开启的进程,实现后台执行的目的。
以下是官方解释
1 2 3 Linux screen命令用于多重视窗管理程序。 screen为多重视窗管理程序。此处所谓的视窗,是指一个全屏幕的文字模式画面。通常只有在使用telnet登入主机或是使用老式的终端机时,才有可能用到screen程序
以及其使用参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 screen [-AmRvx -ls -wipe][-d <作业名称>][-h <行数>][-r <作业名称>][-s <shell>][-S <作业名称>] - -A 将所有的视窗都调整为目前终端机的大小。 - -d<作业名称> 将指定的screen作业离线。 - -h<行数> 指定视窗的缓冲区行数。 - -m 即使目前已在作业中的screen作业,仍强制建立新的screen作业。 - -r<作业名称> 恢复离线的screen作业。 - -R 先试图恢复离线的作业。若找不到离线的作业,即建立新的screen作业。 - -s<shell> 指定建立新视窗时,所要执行的shell。 - -S<作业名称> 指定screen作业的名称。 - -v 显示版本信息。 - -x 恢复之前离线的screen作业。 - -ls或--list 显示目前所有的screen作业。 - -wipe 检查目前所有的screen作业,并删除已经无法使用的screen作业。
其实真实使用时,基本如下几条命令即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 创建一个终端 screen -S ScreenDemo // 在终端中执行自己的脚本 python3 ScreenDemo.py // windows同时按下Ctrl + a + d 即可退出当前screen窗口 // 查看运行中的作业 screen -ls // 进入运行中的作业 screen -r screen_id 例如:2276.pts-3.linux,id就是2276
其实screen在使用过程中也未曾遇到玄学问题,只是由于服务器管理时不方便,所以切换到了另一种后台运行程序
nohup nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
其使用命令也极其简单
1 nohup Command [ Arg … ] [ & ]
不过此处有一个Android上使用nohup的小tag
1 2 3 4 // android nohup nohup `Command` & 通过反点包裹Command会让命令执行更加顺畅
言归正传,回到nohup部署Python项目上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 nohup python3 NohupDemo.py >> /tmp/NohupDemo/LogInfo.log 2>&1 & // 2>&1的含义 0 表示stdin标准输入,用户键盘输入的内容 1 表示stdout标准输出,输出到显示屏的内容 2 表示stderr标准错误,报错内容 2>&1 是一个整体,> 左右不能有空格,即将错误内容重定向输入到标准输出中去。 // 代码整体含义 &为后台运行 第一条代码,以python环境不间断的运行NohupDemo.py这个脚本,并且将脚本输出的内容重定向输入LogInfo.log中(>>意为追加,如果用>会让其中的内容清空) NohupDemo.py >> LogInfo.log 和NohupDemo.py 1>>LogInfo.log相同,只是1(标准输入)被省略了,而后面的LogInfo.log 2>&1 又将2(错误内容)输入到标准输出,然后前面的标准输出又输入到LogInfo.log中,意思错误和标准内容都会输出到LogInfo.log中,其实代码可拆成两块。 nohup python NohupDemo.py 1>> /tmp/NohupDemo/LogInfo.log & nohup python NohupDemo.py 2>> /tmp/NohupDemo/LogInfo.log & 上面代码就是将错误和标准都输出到LogInfo.log,最初的代码只是简化了。 而加2>&1中的&是为了区别文件1和1(标准输出),假如为2>1,那么不就成了将错误内容输出到文件1中。
Python接口部署 Python的接口部署方面,本来想要继续沿用nohup的方式来部署,但是经过大佬指点,接触到了新的知识体系:Supervisor、Gunicorn
Gunicorn Gunicorn 是一个Python WSGI UNIX的HTTP服务器。这是一个pre-fork worker的模型,从Ruby的独角兽(Unicorn )项目移植。该Gunicorn服务器大致与各种Web框架兼容,只需非常简单的执行,轻量级的资源消耗,以及相当迅速。
官方的简介过后,个人使用过程中,其实就是一个很便捷的http接口部署工具,其支持pip的快捷安装,并且运行极其简单,支持flask、Django等轻量级接口框架。
下面我以一个简单的flask app为测试demo介绍Gunicorn的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from flask import Flask, request, jsonifyHttpDemo = Flask(__name__) @HttpDemo.route("/Gunicorn" , methods=["GET" ] def GetGunicorn (): HttpServerStatus = { "success" : 200 , "error" : 10095 } GunicornVersion = request.args.get("GunicornVersion" ) SuccessRespone = "GunicornVersion接受成功:{}" .format (GunicornVersion) ErrorRespone = "GunicornVersion接受失败" if GunicornVersion: return jsonify(content_type="application/json;charset=utf-8" , charset="utf-8" , status="{}" .format (HttpServerStatus["success" ]), content=SuccessRespone) else : return jsonify(content_type="application/json;charset=utf-8" , charset="utf-8" , status="{}" .format (HttpServerStatus["error" ]), content=ErrorRespone)
正常而言,flask想要开启端口并部署接口,需要有一条main去run这个App,如下所示
1 2 if __name__ == "__main__" : HttpDemo.run(host="0.0.0.0" , threaded=True , debug=False , port=8000 )
运行之后就是这样的结构
持久运行、不中断,所以我第一时间想到的就是上文提到的screen以及nohup,但是大佬给了提出了Gunicorn去部署Python接口项目
Gunicorn 安装及使用 此处安装以Ubuntu为例
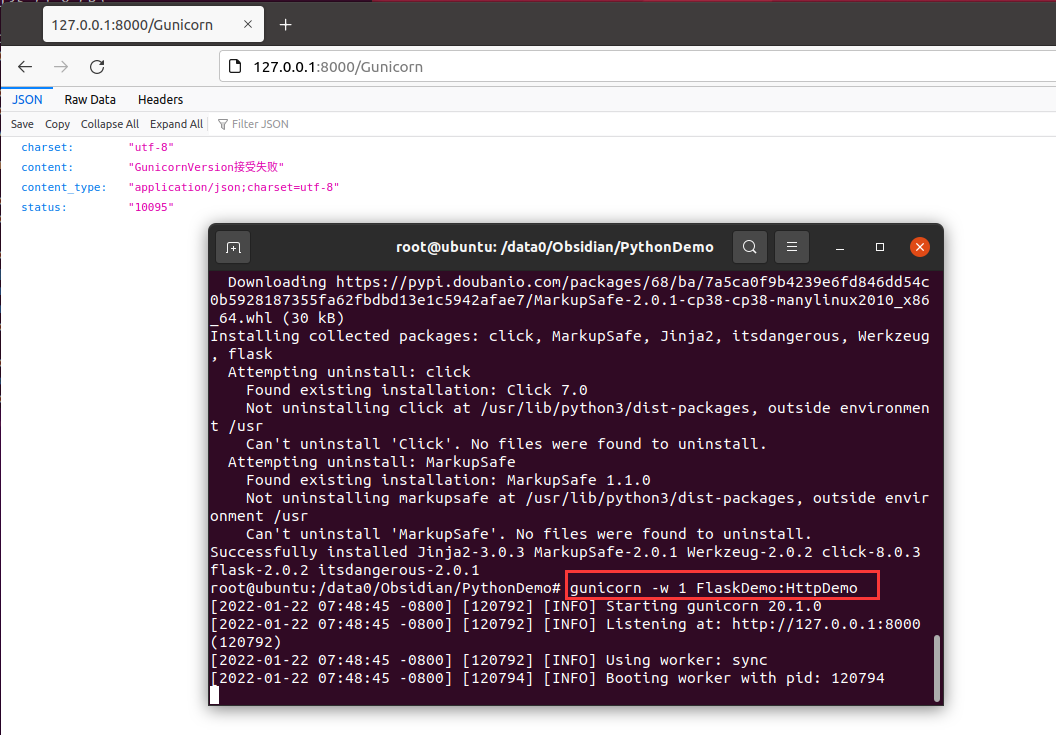
1 2 3 4 5 6 7 8 // pip install gunicorn pip install gunicorn -i https://pypi.douban.com/simple // 最简单的使用gunicorn gunicorn -w 1 FlaskDemo:HttpDemo w后面的数字代表线程的意思 :左边是脚本名称,右边是flask app的名称
使用后如下图所示的效果
但是gunicorn依旧是窗口化的程序,关闭当前窗口,进程也会随之结束,问题又回到了最初的起点
Supervisor Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。
其实说白了他就是一个进程管理系统
Supervisor 安装及使用 此处安装已Ubuntu为例
1 2 3 4 5 // pip install supervisor pip install supervisor -i https://pypi.douban.com/simple // 安装好supervisor之后是没有配置文件的,需要自己手动生成 echo_supervisord_conf > /项目绝对路径/config/supervisor.conf
以下是对supervisor配置文件的详解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 [unix_http_server] file=/tmp/supervisor.sock ; socket文件的路径,supervisorctl用XML_RPC和supervisord通信就是通过它进行 的。如果不设置的话,supervisorctl也就不能用了 不设置的话,默认为none。 非必须设置 ;chmod=0700 ; 这个简单,就是修改上面的那个socket文件的权限为0700 不设置的话,默认为0700。 非必须设置 ;chown=nobody:nogroup ; 这个一样,修改上面的那个socket文件的属组为user.group 不设置的话,默认为启动supervisord进程的用户及属组。非必须设置 ;username=user ; 使用supervisorctl连接的时候,认证的用户 不设置的话,默认为不需要用户。 非必须设置 ;password=123 ; 和上面的用户名对应的密码,可以直接使用明码,也可以使用SHA加密 如:{SHA}82ab876d1387bfafe46cc1c8a2ef074eae50cb1d 默认不设置。。。非必须设置 ;[inet_http_server] ; 侦听在TCP上的socket,Web Server和远程的supervisorctl都要用到他 不设置的话,默认为不开启。非必须设置 ;port=127.0.0.1:9001 ; 这个是侦听的IP和端口,侦听所有IP用 :9001或*:9001。 这个必须设置,只要上面的[inet_http_server]开启了,就必须设置它 ;username=user ; 这个和上面的uinx_http_server一个样。非必须设置 ;password=123 ; 这个也一个样。非必须设置 [supervisord] ;这个主要是定义supervisord这个服务端进程的一些参数的 这个必须设置,不设置,supervisor就不用干活了 logfile=/tmp/supervisord.log ; 这个是supervisord这个主进程的日志路径,注意和子进程的日志不搭嘎。 默认路径$CWD/supervisord.log,$CWD是当前目录。。非必须设置 logfile_maxbytes=50MB ; 这个是上面那个日志文件的最大的大小,当超过50M的时候,会生成一个新的日 志文件。当设置为0时,表示不限制文件大小 默认值是50M,非必须设置。 logfile_backups=10 ; 日志文件保持的数量,上面的日志文件大于50M时,就会生成一个新文件。文件 数量大于10时,最初的老文件被新文件覆盖,文件数量将保持为10 当设置为0时,表示不限制文件的数量。 默认情况下为10。。。非必须设置 loglevel=info ; 日志级别,有critical, error, warn, info, debug, trace, or blather等 默认为info。。。非必须设置项 pidfile=/tmp/supervisord.pid ; supervisord的pid文件路径。 默认为$CWD/supervisord.pid。。。非必须设置 nodaemon=false ; 如果是true,supervisord进程将在前台运行 默认为false,也就是后台以守护进程运行。。。非必须设置 minfds=1024 ; 这个是最少系统空闲的文件描述符,低于这个值supervisor将不会启动。 系统的文件描述符在这里设置cat /proc/sys/fs/file-max 默认情况下为1024。。。非必须设置 minprocs=200 ; 最小可用的进程描述符,低于这个值supervisor也将不会正常启动。 ulimit -u这个命令,可以查看linux下面用户的最大进程数 默认为200。。。非必须设置 ;umask=022 ; 进程创建文件的掩码 默认为022。。非必须设置项 ;user=chrism ; 这个参数可以设置一个非root用户,当我们以root用户启动supervisord之后。 我这里面设置的这个用户,也可以对supervisord进行管理 默认情况是不设置。。。非必须设置项 ;identifier=supervisor ; 这个参数是supervisord的标识符,主要是给XML_RPC用的。当你有多个 supervisor的时候,而且想调用XML_RPC统一管理,就需要为每个 supervisor设置不同的标识符了 默认是supervisord。。。非必需设置 ;directory=/tmp ; 这个参数是当supervisord作为守护进程运行的时候,设置这个参数的话,启动 supervisord进程之前,会先切换到这个目录 默认不设置。。。非必须设置 ;nocleanup=true ; 这个参数当为false的时候,会在supervisord进程启动的时候,把以前子进程 产生的日志文件(路径为AUTO的情况下)清除掉。有时候咱们想要看历史日志,当 然不想日志被清除了。所以可以设置为true 默认是false,有调试需求的同学可以设置为true。。。非必须设置 ;childlogdir=/tmp ; 当子进程日志路径为AUTO的时候,子进程日志文件的存放路径。 默认路径是这个东西,执行下面的这个命令看看就OK了,处理的东西就默认路径 python -c "import tempfile;print tempfile.gettempdir()" 非必须设置 ;environment=KEY="value" ; 这个是用来设置环境变量的,supervisord在linux中启动默认继承了linux的 环境变量,在这里可以设置supervisord进程特有的其他环境变量。 supervisord启动子进程时,子进程会拷贝父进程的内存空间内容。 所以设置的 这些环境变量也会被子进程继承。 小例子:environment=name="haha",age="hehe" 默认为不设置。。。非必须设置 ;strip_ansi=false ; 这个选项如果设置为true,会清除子进程日志中的所有ANSI 序列。什么是ANSI 序列呢?就是我们的\n,\t这些东西。 默认为false。。。非必须设置 ; the below section must remain in the config file for RPC ; (supervisorctl/web interface) to work, additional interfaces may be ; added by defining them in separate rpcinterface: sections [rpcinterface:supervisor] ;这个选项是给XML_RPC用的,当然你如果想使用supervisord或者web server 这 个选项必须要开启的 supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface [supervisorctl] ;这个主要是针对supervisorctl的一些配置 serverurl=unix:///tmp/supervisor.sock ; 这个是supervisorctl本地连接supervisord的时候,本地UNIX socket 路径,注意这个是和前面的[unix_http_server]对应的 默认值就是unix:///tmp/supervisor.sock。。非必须设置 ;serverurl=http://127.0.0.1:9001 ; 这个是supervisorctl远程连接supervisord的时候,用到的TCP socket路径 注意这个和前面的[inet_http_server]对应 默认就是http://127.0.0.1:9001。。。非必须项 ;username=chris ; 用户名 默认空。。非必须设置 ;password=123 ; 密码 默认空。。非必须设置 ;prompt=mysupervisor ; 输入用户名密码时候的提示符 默认supervisor。。非必须设置 ;history_file=~/.sc_history ; 这个参数和shell中的history类似,我们可以用上下键来查找前面执行过的命令 默认是no file的。。所以我们想要有这种功能,必须指定一个文件。。。非 必须设置 ; The below sample program section shows all possible program subsection values, ; create one or more 'real' program: sections to be able to control them under ; supervisor. ;[program:theprogramname] ;这个就是咱们要管理的子进程了,":"后面的是名字,最好别乱写和实际进程 有点关联最好。这样的program我们可以设置一个或多个,一个program就是 要被管理的一个进程 ;command=/bin/cat ; 这个就是我们的要启动进程的命令路径了,可以带参数 例子:/home/test.py -a 'hehe' 有一点需要注意的是,我们的command只能是那种在终端运行的进程,不能是 守护进程。这个想想也知道了,比如说command=service httpd start。 httpd这个进程被linux的service管理了,我们的supervisor再去启动这个命令 这已经不是严格意义的子进程了。 这个是个必须设置的项 ;process_name=%(program_name)s ; 这个是进程名,如果我们下面的numprocs参数为1的话,就不用管这个参数 了,它默认值%(program_name)s也就是上面的那个program冒号后面的名字, 但是如果numprocs为多个的话,那就不能这么干了。想想也知道,不可能每个 进程都用同一个进程名吧。 ;numprocs=1 ; 启动进程的数目。当不为1时,就是进程池的概念,注意process_name的设置 默认为1 。。非必须设置 ;directory=/tmp ; 进程运行前,会前切换到这个目录 默认不设置。。。非必须设置 ;umask=022 ; 进程掩码,默认none,非必须 ;priority=999 ; 子进程启动关闭优先级,优先级低的,最先启动,关闭的时候最后关闭 默认值为999 。。非必须设置 ;autostart=true ; 如果是true的话,子进程将在supervisord启动后被自动启动 默认就是true 。。非必须设置 ;autorestart=unexpected ; 这个是设置子进程挂掉后自动重启的情况,有三个选项,false,unexpected 和true。如果为false的时候,无论什么情况下,都不会被重新启动, 如果为unexpected,只有当进程的退出码不在下面的exitcodes里面定义的退 出码的时候,才会被自动重启。当为true的时候,只要子进程挂掉,将会被无 条件的重启 ;startsecs=1 ; 这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启 动成功了 默认值为1 。。非必须设置 ;startretries=3 ; 当进程启动失败后,最大尝试启动的次数。。当超过3次后,supervisor将把 此进程的状态置为FAIL 默认值为3 。。非必须设置 ;exitcodes=0,2 ; 注意和上面的的autorestart=unexpected对应。。exitcodes里面的定义的 退出码是expected的。 ;stopsignal=QUIT ; 进程停止信号,可以为TERM, HUP, INT, QUIT, KILL, USR1, or USR2等信号 默认为TERM 。。当用设定的信号去干掉进程,退出码会被认为是expected 非必须设置 ;stopwaitsecs=10 ; 这个是当我们向子进程发送stopsignal信号后,到系统返回信息 给supervisord,所等待的最大时间。 超过这个时间,supervisord会向该 子进程发送一个强制kill的信号。 默认为10秒。。非必须设置 ;stopasgroup=false ; 这个东西主要用于,supervisord管理的子进程,这个子进程本身还有 子进程。那么我们如果仅仅干掉supervisord的子进程的话,子进程的子进程 有可能会变成孤儿进程。所以咱们可以设置可个选项,把整个该子进程的 整个进程组都干掉。 设置为true的话,一般killasgroup也会被设置为true。 需要注意的是,该选项发送的是stop信号 默认为false。。非必须设置。。 ;killasgroup=false ; 这个和上面的stopasgroup类似,不过发送的是kill信号 ;user=chrism ; 如果supervisord是root启动,我们在这里设置这个非root用户,可以用来 管理该program 默认不设置。。。非必须设置项 ;redirect_stderr=true ; 如果为true,则stderr的日志会被写入stdout日志文件中 默认为false,非必须设置 ;stdout_logfile=/a/path ; 子进程的stdout的日志路径,可以指定路径,AUTO,none等三个选项。 设置为none的话,将没有日志产生。设置为AUTO的话,将随机找一个地方 生成日志文件,而且当supervisord重新启动的时候,以前的日志文件会被 清空。当 redirect_stderr=true的时候,sterr也会写进这个日志文件 ;stdout_logfile_maxbytes=1MB ; 日志文件最大大小,和[supervisord]中定义的一样。默认为50 ;stdout_logfile_backups=10 ; 和[supervisord]定义的一样。默认10 ;stdout_capture_maxbytes=1MB ; 这个东西是设定capture管道的大小,当值不为0的时候,子进程可以从stdout 发送信息,而supervisor可以根据信息,发送相应的event。 默认为0,为0的时候表达关闭管道。。。非必须项 ;stdout_events_enabled=false ; 当设置为ture的时候,当子进程由stdout向文件描述符中写日志的时候,将 触发supervisord发送PROCESS_LOG_STDOUT类型的event 默认为false。。。非必须设置 ;stderr_logfile=/a/path ; 这个东西是设置stderr写的日志路径,当redirect_stderr=true。这个就不用 设置了,设置了也是白搭。因为它会被写入stdout_logfile的同一个文件中 默认为AUTO,也就是随便找个地存,supervisord重启被清空。。非必须设置 ;stderr_logfile_maxbytes=1MB ; 这个出现好几次了,就不重复了 ;stderr_logfile_backups=10 ; 这个也是 ;stderr_capture_maxbytes=1MB ; 这个一样,和stdout_capture一样。 默认为0,关闭状态 ;stderr_events_enabled=false ; 这个也是一样,默认为false ;environment=A="1",B="2" ; 这个是该子进程的环境变量,和别的子进程是不共享的 ;serverurl=AUTO ; ; The below sample eventlistener section shows all possible ; eventlistener subsection values, create one or more 'real' ; eventlistener: sections to be able to handle event notifications ; sent by supervisor. ;[eventlistener:theeventlistenername] ;这个东西其实和program的地位是一样的,也是suopervisor启动的子进 程,不过它干的活是订阅supervisord发送的event。他的名字就叫 listener了。我们可以在listener里面做一系列处理,比如报警等等 楼主这两天干的活,就是弄的这玩意 ;command=/bin/eventlistener ; 这个和上面的program一样,表示listener的可执行文件的路径 ;process_name=%(program_name)s ; 这个也一样,进程名,当下面的numprocs为多个的时候,才需要。否则默认就 OK了 ;numprocs=1 ; 相同的listener启动的个数 ;events=EVENT ; event事件的类型,也就是说,只有写在这个地方的事件类型。才会被发送 ;buffer_size=10 ; 这个是event队列缓存大小,单位不太清楚,楼主猜测应该是个吧。当buffer 超过10的时候,最旧的event将会被清除,并把新的event放进去。 默认值为10。。非必须选项 ;directory=/tmp ; 进程执行前,会切换到这个目录下执行 默认为不切换。。。非必须 ;umask=022 ; 淹没,默认为none,不说了 ;priority=-1 ; 启动优先级,默认-1,也不扯了 ;autostart=true ; 是否随supervisord启动一起启动,默认true ;autorestart=unexpected ; 是否自动重启,和program一个样,分true,false,unexpected等,注意 unexpected和exitcodes的关系 ;startsecs=1 ; 也是一样,进程启动后跑了几秒钟,才被认定为成功启动,默认1 ;startretries=3 ; 失败最大尝试次数,默认3 ;exitcodes=0,2 ; 期望或者说预料中的进程退出码, ;stopsignal=QUIT ; 干掉进程的信号,默认为TERM,比如设置为QUIT,那么如果QUIT来干这个进程 那么会被认为是正常维护,退出码也被认为是expected中的 ;stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10) ;stopasgroup=false ; send stop signal to the UNIX process group (default false) ;killasgroup=false ; SIGKILL the UNIX process group (def false) ;user=chrism ;设置普通用户,可以用来管理该listener进程。 默认为空。。非必须设置 ;redirect_stderr=true ; 为true的话,stderr的log会并入stdout的log里面 默认为false。。。非必须设置 ;stdout_logfile=/a/path ; 这个不说了,好几遍了 ;stdout_logfile_maxbytes=1MB ; 这个也是 ;stdout_logfile_backups=10 ; 这个也是 ;stdout_events_enabled=false ; 这个其实是错的,listener是不能发送event ;stderr_logfile=/a/path ; 这个也是 ;stderr_logfile_maxbytes=1MB ; 这个也是 ;stderr_logfile_backups ; 这个不说了 ;stderr_events_enabled=false ; 这个也是错的,listener不能发送event ;environment=A="1",B="2" ; 这个是该子进程的环境变量 默认为空。。。非必须设置 ;serverurl=AUTO ; override serverurl computation (childutils) ; The below sample group section shows all possible group values, ; create one or more 'real' group: sections to create "heterogeneous" ; process groups. ;[group:thegroupname] ;这个东西就是给programs分组,划分到组里面的program。我们就不用一个一个去操作了 我们可以对组名进行统一的操作。 注意:program被划分到组里面之后,就相当于原来 的配置从supervisor的配置文件里消失了。。。supervisor只会对组进行管理,而不再 会对组里面的单个program进行管理了 ;programs=progname1,progname2 ; 组成员,用逗号分开 这个是个必须的设置项 ;priority=999 ; 优先级,相对于组和组之间说的 默认999。。非必须选项 ; The [include] section can just contain the "files" setting. This ; setting can list multiple files (separated by whitespace or ; newlines). It can also contain wildcards. The filenames are ; interpreted as relative to this file. Included files *cannot* ; include files themselves. ;[include] ;这个东西挺有用的,当我们要管理的进程很多的时候,写在一个文件里面 就有点大了。我们可以把配置信息写到多个文件中,然后include过来 ;files = relative/directory/*.ini
其实配置文件无需整体都有用,现阶段需要修改的配置只有如下几点,还有一点注意的,配置文件中,字段前面的“;”代表注释 的意思,所以想要启用这条字段,需要将前面的封号删除
1 2 3 4 5 6 7 8 9 10 11 12 13 [supervisord] logfile=Log/supervisord.log ; logfile_maxbytes=50MB ; logfile_backups=10 ; loglevel=info ; pidfile=Log/supervisord.pid ; nodaemon=false ; silent=false ; minfds=1024 ; minprocs=200 ; [include] files = *.ini
其中include中的内容说明配置进程的管理,既然说明为ini文件,那么接下里编写对应的ini文件即可,如下所示,编写一个gunicorn运行的flask http接口
1 2 3 4 5 6 7 8 9 [program:HttpDemo] directory = /data0/Obsidian/PythonDemo command = gunicorn -w 1 -b 127.0.0.1:10000 FlaskDemo:HttpDemo enviroment = PATH="/data0/Obsidian/PythonDemo/venv/bin" autostart = true autorestart = true startsecs = 10 stopwaitsecs = 60 priority = 999
项目ini的配置文件中,我把项目运行地址设定到了127上,然后写明了Python的venv环境,此处可以算是一个Python项目编写的小建议吧:
Python项目编写时,尽量做到每个项目有其自身的虚拟环境,这个习惯用过的都说好;当然demo例外
项目部署时,最好配合Nginx,项目配置到127的环回地址,然后Nginx做代理
书归正传,上述配置文件之后我们可以的配置文件路径如下:
supervisord.conf:/项目绝对路径/Config/supervisord.conf
HttpDemo.ini:/项目绝对路径/Config/HttpDemo.ini
此时,绝对路径保持在Config下,开始执行”supervisord”命令即可
1 2 3 4 5 6 7 // 使用自身修改的配置文件启动supervisor supervisord -c supervisord.conf // 启动flask app supervisorctl start HttpDemo 注意,start之后的app是 ini配置文件中,第一行“program”参数之后的名儿
至此,flask项目已经成功挂载,pid文件存放位置可查看运行的pid
supervisord 报错处理 Error: .ini file does not include supervisorctl section
这个的报错原因依据网上大佬们解释是conf文件中缺少了[supervisord]和[supervisorctl]这俩个固有模块,所以本人的解决方案就是,删除自己的配置,通过echo_supervisord_conf再去生成一个配置文件,此次生成的配置文件只修改如下俩点:
[supervisord]模块下的“logfile”和“pidfile”方便进行日志管理和pid管理
[include]去掉注释,“files”参数后面填写自己配置文件的路径
Error: The directory named as part of the path Log/supervisord.log does not exist
这个报错就有点耐人寻味,意味着我的相对路径没有找到,demo项目设置时,用于存储supervisord.conf文件的Config文件夹和Log文件夹是同级目录,相关结构如下
1 2 3 4 5 6 7 8 9 10 - PythonDemo | - Config | - supervisord.conf | - FlaskDemo.ini | - Log | - FlaskDemo.py
不过这个问题很好解决,只需要相对路劲改成绝对路劲即可
参考文献 python supervisord 使用
supervisord ini文件报错
Supervisor 配置过程